【导读】DeepSeek一天能赚几多钱?官方忽然揭秘!潞晨科技停息DeepSeek API效劳中国基金报记者 泰勒各人好,一同存眷一下对于DeepSeek的最新新闻!DeepSeek初次表露:实践本钱利润率545%当市场认为DeepSeek的开源周内容宣布结束之后,3月1日,DeepSeek发布了“One More Thing”,忽然揭秘V3/R1推理系統,公然了年夜范围安排本钱跟收益。
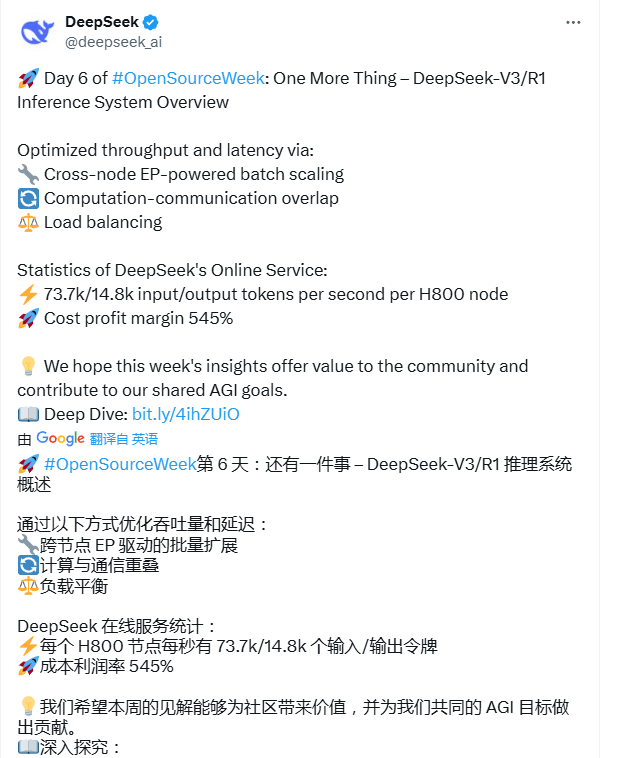
据官方表露, DeepSeek-V3/R1推理体系的优化目的是:更年夜的吞吐,更低的耽误。为了实现这两个目的,DeepSeek应用年夜范围跨节点专家并行(Expert Parallelism / EP)。起首EP使得batch size年夜年夜增添,从而进步GPU矩阵乘法的效力,进步吞吐。其次EP使得专家疏散在差别的GPU上,每个 GPU 只要要盘算很少的专家(因而更少的访存需要),从而下降耽误。但EP同时也增添了体系的庞杂性。庞杂性重要表现在两个方面:EP引入跨节点的传输。为了优化吞吐,须要计划适合的盘算流程使得传输跟盘算能够同步停止。EP波及多个节点,因而自然须要Data Parallelism(DP),差别的DP之间须要停止负载平衡。因而,DeepSeek先容了怎样应用EP增年夜batch size,怎样暗藏传输的耗时,怎样停止负载平衡。年夜范围跨节点专家并行(Expert Parallelism / EP)因为DeepSeek-V3/R1的专家数目浩繁,而且每层256个专家中仅激活此中8个。模子的高度稀少性决议了必需采取很年夜的overall batch size,才干给每个专家供给充足的expert batch size,从而实现更年夜的吞吐、更低的延时。须要年夜范围跨节点专家并行(Expert Parallelism / EP)。 开展全文 采取多机多卡间的专家并行战略来到达以下目标:Prefill:路由专家EP32、MLA跟共享专家DP32,一个安排单位是4节点,32个冗余路由专家,每张卡9个路由专家跟1个共享专家。 Decode:路由专家EP144、MLA跟共享专家DP144,一个安排单位是18 节点,32个冗余路由专家,每张卡2个路由专家跟1个共享专家。 盘算通讯堆叠 多机多卡的专家并行会引入比拟年夜的通讯开支,以是应用了双batch堆叠来掩饰通讯开支,进步团体吞吐。 对prefill阶段,两个batch的盘算跟通讯交织停止,一个batch在停止盘算的时间能够去掩饰另一个batch的通讯开支; 对decode阶段,差别阶段的履行时光有所差异,以是把attention局部拆成了两个stage,合计5个stage的流水线来实现盘算跟通讯的堆叠。尽可能地负载平衡 因为采取了很年夜范围的并行(包含数据并行跟专家并行),假如某个GPU的盘算或通讯负载过重,将成为机能瓶颈,拖慢全部体系;同时其余GPU由于等候而空转,形成团体应用率降落。因而须要尽可能地为每个GPU调配平衡的盘算负载、通讯负载。 PrefillLoadBalancer 中心成绩:差别数据并行(DP)实例上的恳求个数、长度差别,招致core-attention盘算量、dispatch发送量也差别。 优化目的:各GPU的盘算量只管雷同(core-attention盘算负载平衡)、输入的token数目也只管雷同(dispatch发送量负载平衡),防止局部GPU处置时光过长。 中心成绩:差别数据并行(DP)实例上的恳求数目、长度差别,招致core-attention盘算量(与KVCache占用量相干)、dispatch发送量差别。 优化目的:各GPU的KVCache占用量只管雷同(core-attention盘算负载平衡)、恳求数目只管雷同(dispatch发送量负载平衡)。 中心成绩:对给定MoE模子,存在一些自然的高负载专家(expert),招致差别GPU的专家盘算负载不平衡。 优化目的:每个GPU上的专家盘算量平衡(即最小化全部GPU的dispatch接受量的最年夜值)。 中心成绩:差别数据并行(DP)实例上的恳求个数、长度差别,招致core-attention盘算量、dispatch发送量也差别。 优化目的:各GPU的盘算量只管雷同(core-attention盘算负载平衡)、输入的token数目也只管雷同(dispatch发送量负载平衡),防止局部GPU处置时光过长。 中心成绩:差别数据并行(DP)实例上的恳求个数、长度差别,招致core-attention盘算量、dispatch发送量也差别。 优化目的:各GPU的盘算量只管雷同(core-attention盘算负载平衡)、输入的token数目也只管雷同(dispatch发送量负载平衡),防止局部GPU处置时光过长。 DecodeLoadBalancer 中心成绩:差别数据并行(DP)实例上的恳求数目、长度差别,招开元娱乐棋牌官方网站致core-attention盘算量(与KVCache占用量相干)、dispatch发送量差别。 优化目的:各GPU的KVCache占用量只管雷同(core-attention盘算负载平衡)、恳求数目只管雷同(dispatch发送量负载平衡)。 中心成绩:差别数据并行(DP)实例上的恳求数目、长度差别,招致core-attention盘算量(与KVCache占用量相干)、dispatch发送量差别。 优化目的:各GPU的KVCache占用量只管雷同(core-attention盘算负载平衡)、恳求数目只管雷同(dispatch发送量负载平衡)。 Expert-ParallelLoadBalancer 中心成绩:对给定MoE模子,存在一些自然的高负载专家(expert),招致差别GPU的专家盘算负载不平衡。 优化目的:每个GPU上的专家盘算量平衡(即最小化全部GPU的dispatch接受量的最年夜值)。 中心成绩:对给定MoE模子,存在一些自然的高负载专家(expert),招致差别GPU的专家盘算负载不平衡。 优化目的:每个GPU上的专家盘算量平衡(即最小化全部GPU的dispatch接受量的最年夜值)。



